Logical Diagrams for Multi-Site Failover
Introduction
This document offer logical diagrams associated with Multi-Site Failover. By visualizing key failover and failback paths, and outlining step-by-step processes, this guide serves as a resource for understanding and implementing Multi-Site Failover configurations.
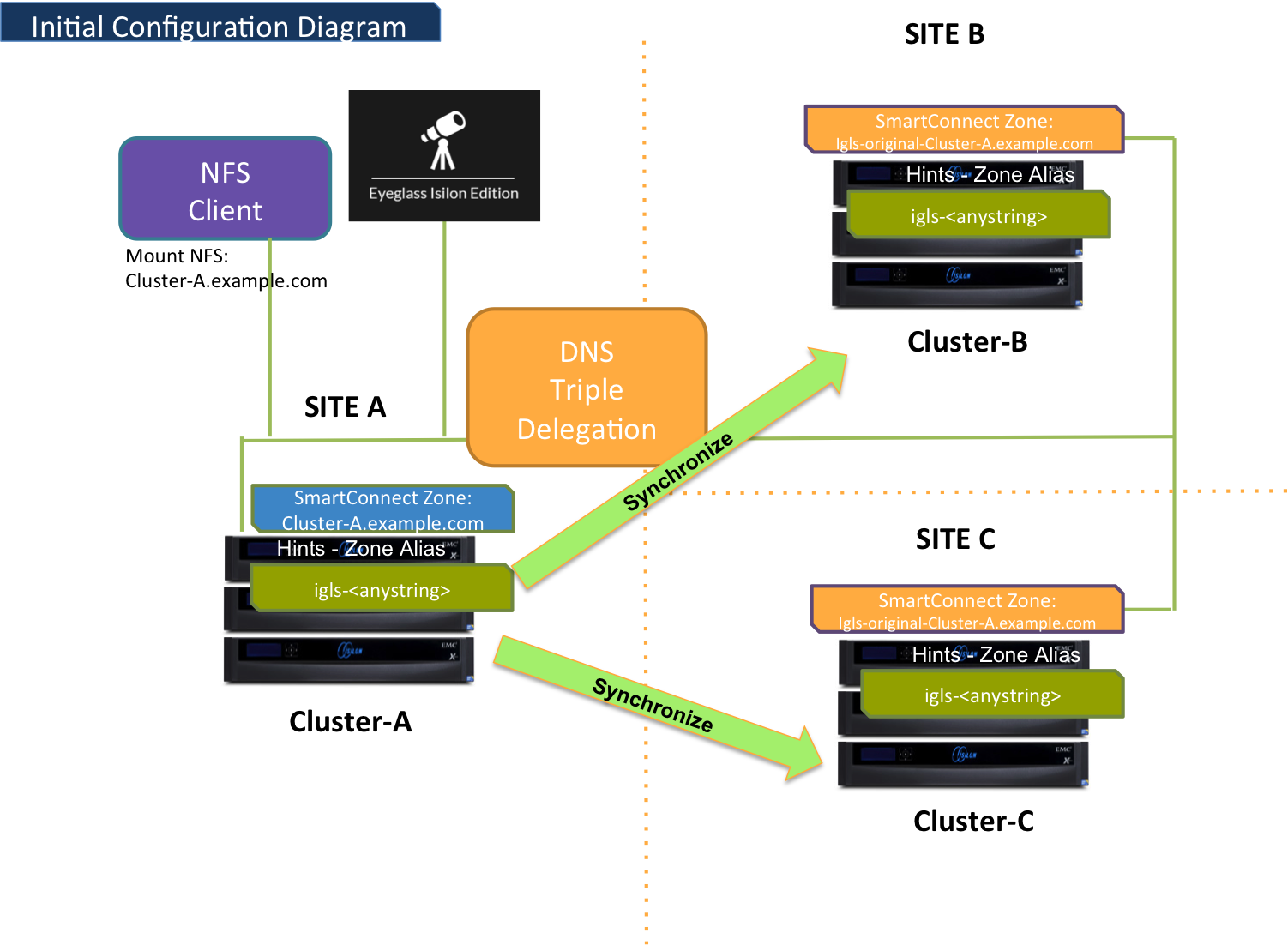
Initial Configuration
The following outlines the initial configuration for a three-site failover setup:
- Site A: Serves as the Primary Site, hosting the active data and services.
- Site B: Designated as Secondary Site #1, configured to take over during failover events.
- Site C: Designated as Secondary Site #2, providing an additional failover option.
This setup ensures that all sites are synchronized and prepared for a seamless transition during a failover, with DNS triple delegation enabling communication between the clusters.
Failover and Failback Paths
This section provides an overview of the failover and failback paths between the primary site (Site A) and the two secondary sites (Site B and Site C). Each path outlines the sequence of actions required to transition data and services during failover events and restore operations during failback. Detailed workflows for each scenario—Site A to Site B, Site A to Site C, and their respective failbacks—are described in the Failover and Failback Steps section. These paths ensure continuity and data integrity across all three sites.
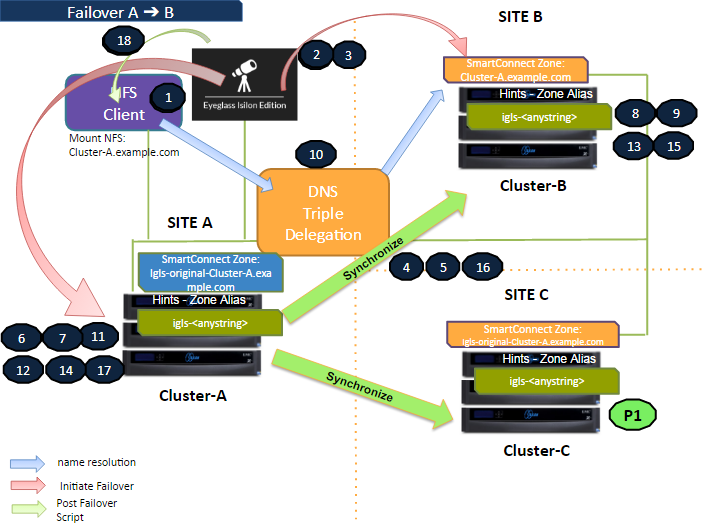
Failover Site A to Site B
The following diagram illustrates the workflow for failover from Site A (Primary) to Site B (Secondary #1). Ensure that step P1 (Preparation Step - prior to initiating Eyeglass Access Zone Failover) is completed before starting the failover process. Details on this procedure can be found in the Failover Steps section below.
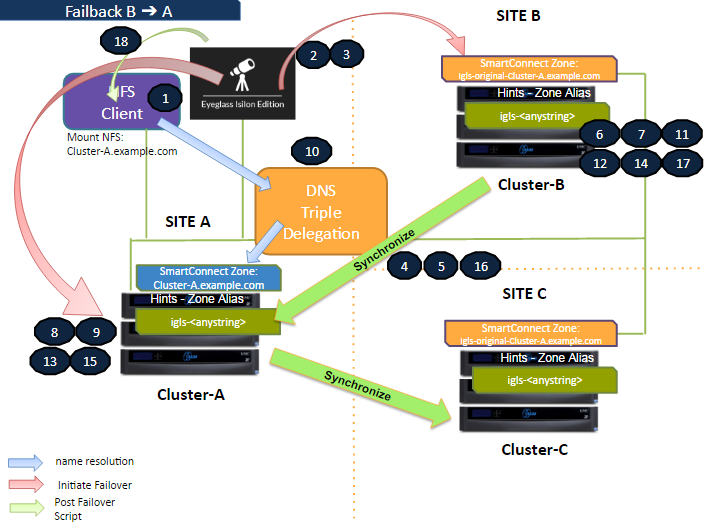
Failback Site B to Site A
The following diagram illustrates the workflow for failback from Site B (Secondary #1) to Site A (Primary). This process restores the primary site's operations following a failover event. Details on the procedure can be found in the Failback Steps section below.
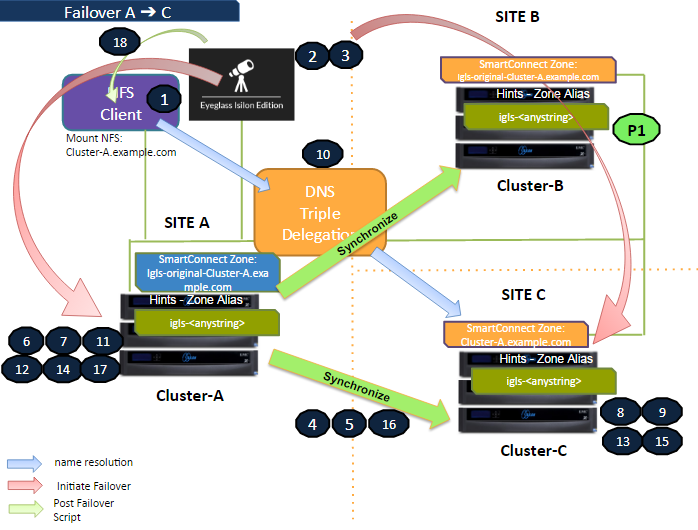
Failover Site A to Site C
The following diagram illustrates the workflow for failover from Site A (Primary) to Site C (Secondary #2). Ensure that step P1 (Preparation Step - prior to initiating Eyeglass Access Zone Failover) is completed before starting the failover process. For a detailed explanation of each step, refer to the Failover Steps section.
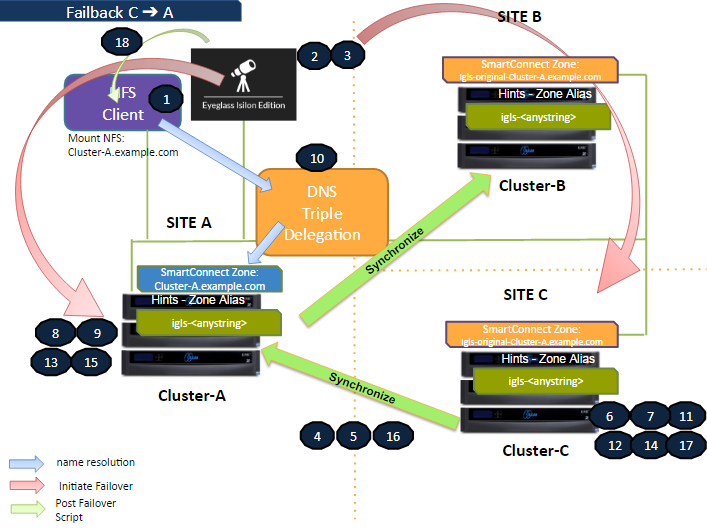
Failback Site C to Site A
The following diagram illustrates the workflow for failback from Site C (Secondary #2) to Site A (Primary). This process restores the primary site's operations following a failover event. For a detailed explanation of each step, refer to the Failback Steps section.
Failover and Failback Steps
Failover Steps
Preparation Step:
- For Failover A ⇒ B: Ensure there are no existing Mirror Policies between Site C and Site A. If Mirror Policies exist between Site C and Site A, delete them before initiating Failover from Site A to Site B.
- For Failover A ⇒ C: Ensure there are no existing Mirror Policies between Site B and Site A. If Mirror Policies exist between Site B and Site A, delete them before initiating Failover from Site A to Site C.
- Ensure that there is no live access to data.
- Begin the failover process.
- Perform validation checks.
- Synchronize data between the clusters.
- Synchronize configurations (shares, exports, aliases).
- Change the SmartConnect Zone on the source to prevent resolution by clients.
- Avoid SPN collisions during the process.
- Move the SmartConnect Zone to the target cluster.
- Update the SPN to allow authentication against the target cluster.
- Update DNS to point to the target cluster using DNS triple delegation.
- Record the schedule for SyncIQ policies being failed over.
- Prevent failed-over SyncIQ policies from running.
- Allow write access to data on the target cluster.
- Disable SyncIQ on the source cluster and make it active on the target.
- Set the appropriate SyncIQ schedule on the target cluster.
- Synchronize quota configurations.
- Remove quotas on directories that are the target of SyncIQ (PowerScale best practice).
- Refresh the session to pick up DNS changes (use the post-failover script).
Failback Steps
- Ensure that there is no live access to data.
- Begin the failback process.
- Perform validation checks.
- Synchronize data between the clusters.
- Synchronize configurations (shares, exports, aliases).
- Change the SmartConnect Zone on the source (secondary cluster) to prevent resolution by clients.
- Avoid SPN collisions during the process.
- Move the SmartConnect Zone to the target (primary cluster).
- Update the SPN to allow authentication against the target cluster.
- Update DNS to point to the target cluster using DNS triple delegation.
- Record the schedule for SyncIQ policies being failed back.
- Prevent failed-back SyncIQ policies from running.
- Allow write access to data on the target cluster.
- Disable SyncIQ on the source cluster (secondary) and make it active on the target cluster (primary).
- Set the appropriate SyncIQ schedule on the target cluster (primary).
- Synchronize quota configurations.
- Remove quotas on directories that are the target of SyncIQ (on the secondary cluster) as per PowerScale best practices.
- Refresh the session to pick up DNS changes (use the post-failback script).